Understanding R1-Zero-Like Training: A Critical Perspective
简介:
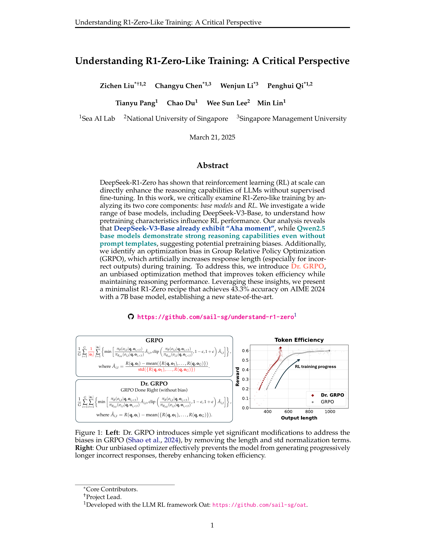
DeepSeek-R1-Zero 表明,大规模强化学习 (RL) 可以直接增强 LLM 的推理能力,而无需监督微调。在这项工作中,我们通过分析其两个核心组件:基础模型和 RL,严格审查了类似 R1-Zero 的训练。我们研究了包括 DeepSeek-V3-Base 在内的各种基础模型,以了解预训练特性如何影响 RL 性能。我们的分析表明,DeepSeek-V3-Base 已经表现出“顿悟时刻”,而 Qwen2.5 基础模型即使没有提示模板也表现出强大的推理能力,这表明存在潜在的预训练偏差。此外,我们在组相对策略优化 (GRPO) 中发现了优化偏差,它在训练期间人为地增加了响应长度(尤其是对于不正确的输出)。为了解决这个问题,我们引入了 Dr. GRPO,这是一种无偏优化方法,可以在保持推理性能的同时提高 token 效率。利用这些见解,我们提出了一种极简的 R1-Zero 方案,该方案使用 7B 基础模型在 AIME 2024 上实现了 43.3% 的准确率,建立了新的最先进水平。
英文简介:
DeepSeek-R1-Zero has shown that reinforcement learning (RL) at scale can directly enhance the reasoning capabilities of LLMs without supervised fine-tuning. In this work, we critically examine R1-Zero-like training by analyzing its two core components: base models and RL. We investigate a wide range of base models, including DeepSeek-V3-Base, to understand how pretraining characteristics influence RL performance. Our analysis reveals that DeepSeek-V3-Base already exhibit “Aha moment”, while Qwen2.5 base models demonstrate strong reasoning capabilities even without prompt templates, suggesting potential pretraining biases. Additionally, we identify an optimization bias in Group Relative Policy Optimization (GRPO), which artificially increases response length (especially for incorrect outputs) during training. To address this, we introduce Dr. GRPO, an unbiased optimization method that improves token efficiency while maintaining reasoning performance. Leveraging these insights, we present a minimalist R1-Zero recipe that achieves 43.3% accuracy on AIME 2024 with a 7B base model, establishing a new state-of-the-art.
- 书名
- Understanding R1-Zero-Like Training: A Critical Perspective
- 语言
- 英语
- 年份
- 2025
- 页数
- 19页
- 大小
- 995.67 kB
- 标签
- 机器学习
- 下载
 Understanding R1-Zero-Like Training: A Critical Perspective.pdf
Understanding R1-Zero-Like Training: A Critical Perspective.pdf- 密码
- 65536
最后更新:2025-04-12 23:58:19
←Concise Machine Learning by Jonathan Richard Shewchuk
→Chunking Attacks on File Backup Services using Content-Defined Chunking